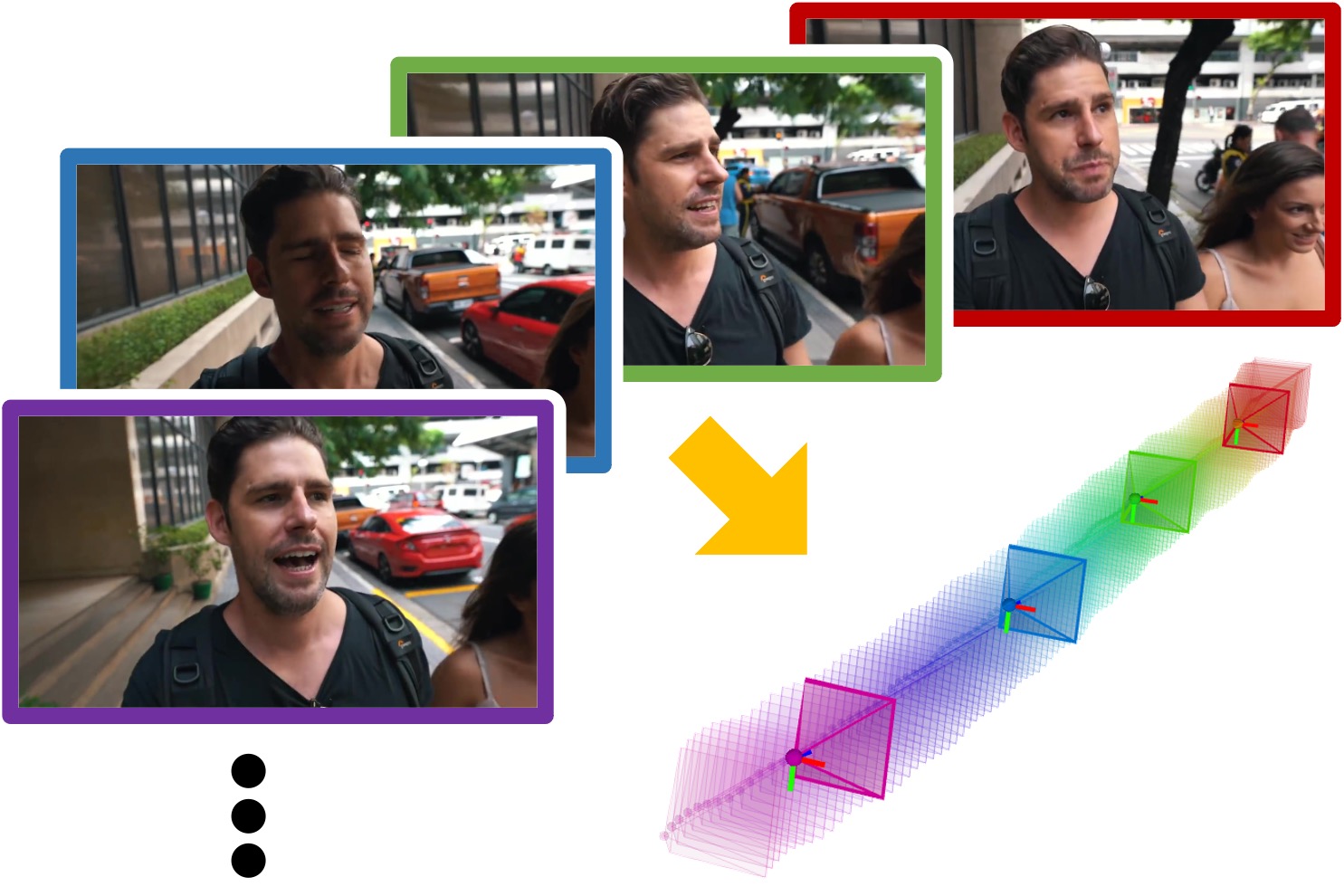
Dynamic Camera Poses and Where to Find Them
CVPR 2025

paper •
project page •
dataset •
BibTex (show)
@inproceedings{rockwell2025dynamic,
title={Dynamic Camera Poses and Where to Find Them},
author={Rockwell, Chris and Tung, Joseph and Lin, Tsung-Yi and Liu, Ming-Yu and Fouhey, David F. and Lin, Chen-Hsuan},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition ({CVPR})},
year={2025}
}
title={Dynamic Camera Poses and Where to Find Them},
author={Rockwell, Chris and Tung, Joseph and Lin, Tsung-Yi and Liu, Ming-Yu and Fouhey, David F. and Lin, Chen-Hsuan},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition ({CVPR})},
year={2025}
}


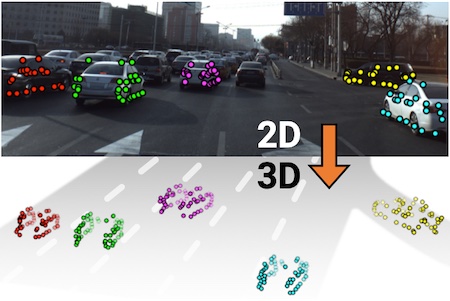
DynPose-100K is a large-scale dynamic Internet video dataset annotated with camera information. It contains diverse and dynamic video content annotated with a state-of-the-art camera pose estimation pipeline.